SGD Text classification
This project is aimed at developing a well-tuned, robust, scalable and accurate recommender system. Text classification and analysis is a major application field for machine learning algorithms, especially in extraction of binary information, i.e., positive or negative attitude towards the new tax plan from president, thumb up or down against a recently released movie, or even to recommend or not to recommend a freshly brewed beer. Such information that reflects the critiques is always hidden behind lines and lines of texts, which need to be decoded and classified so that large amount of text data could be further processed by the computer, so that people could utilize machine learning algorithms to reveal and extract the intrinsic statistics of text.
Based on “Large Movie Review Dataset”, containing 50,000 reviews, I have evaluated the selection of hyperparameters in Neural Networks using Stochastic Gradient Descent.
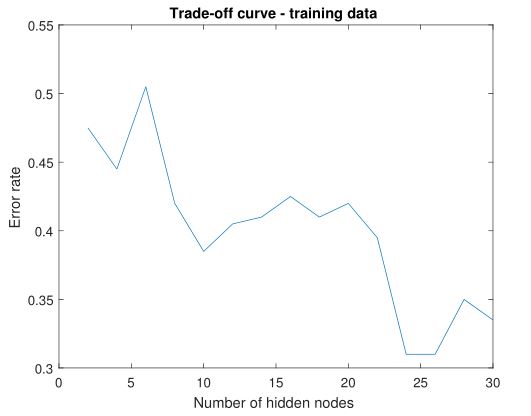
In the first plot, I illustrate the performance of neural network with respect to different number of nodes in hidden layer while setting learning rate at 0.1, randomized SGD. The error rate initially decreases with the increase of nodes in hidden layer but after the number reaches 25, error rate bounces up and continue to increase. I also implemented stratified cross-validation of 10 folds, with learning rate 0.1, number of hidden nodes 25.
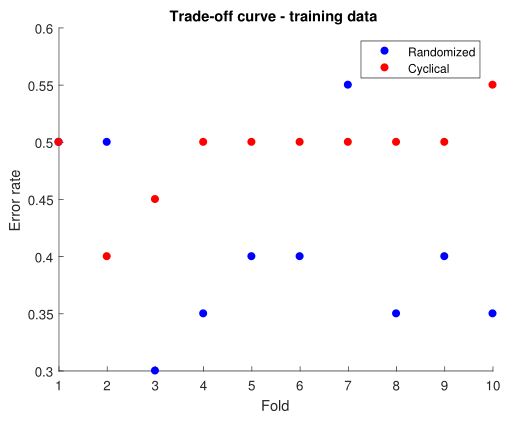
The second plot is a scatter plot of error rate for each fold. On average randomized SGD performs better than cyclic. Preliminary stage of model tuning provides clear guidelines and benchmark for further improvement over model efficiency in the future.
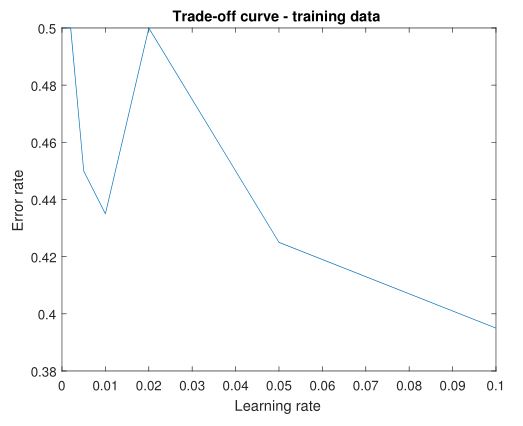
In tuning learning rate, I fixed number of hidden nodes at 25 and applied randomized SGD. From Plot 3, it can be observed a rough decline of error rate on the range of 0 to 0.1. Intuitive drawback of too small learning rate is the model converges more slowly and thus results in higher error rate. On the other hand, learning rate cannot be too large either, which will make our model too volatile.